记一次线上 mysql 内存持续上涨导致的 oom
Contents
告警
我们的一个 MySQL 实例告警(简称为 实例1), 内存占用率已经达到 90% 以上, 并且持续缓慢上涨当中. 如果占用率达到 100%, 实例将有 OOM 重启的风险.
现象
MySQL 实例使用的是阿里云家的服务, 通过查看阿里云的监控图表, 发现内存使用率长期来都在持续上涨, 且趋势缓慢. 总内存 16GB, 一个月时间能上涨约 7%, 也就是说一个月吃掉 1.12GB 的内存.
再看看 MySQL 其他方面的性能指标:
- CPU使用率: CPU平均利用率为 14.6%,最大利用率 33.2%
正常 - IOPS: IOPS平均为 90.38,最大为1125.67, 允许的最大IOPS为8000
正常 - 连接数: 一直平稳在 750 上下, 连接使用率 16.3% (上限 4000)
不算很高 - 慢查询: 当前时间段慢SQL数量为9
不多, 执行频率低
初步分析
MySQL 实例内存占用依然在上涨, 告警不断. 为了找到问题的线索, 我开始从业务侧进行了排查.
首先, 我查看了业务 server 与 MySQL实例建立的 TCP 连接状态, 几乎都处于 ESTABLISHED 状态, 数量与阿里云监控一致.
python 32672 user 17u IPv4 2559918672 0t0 TCP server-app3:41162->172.17.0.81:mysql (ESTABLISHED)
另外, 业务日志中也没有 MySQL 相关错误日志. 说明我们业务侧使用的连接池正常, 不是连接池组件的问题.
然后, 查看了阿里云记录的慢查询 SQL 对应的业务代码, 确认是低频操作, 可以适当优化索引, 但也不至于导致内存一直上涨.
业务侧暂时没发现什么问题, 运维同事建议是修改 innodb_buffer_pool_size, 从 75% 改到 50%, 不过会重启 MySQL, 内存是会降下去的.
因为我们使用的是 MySQL 新版本, 支持 performance_schema, 我在 performance_schema 中查到 MySQL innodb_buffer_pool 确实已经达到了 75%的使用上限, 不过已经没有继续往上增加了, 因此认为这还不是问题的根本原因.
其他发现
我们的另外一个阿里云 MySQL 实例(简称为 实例2), 使用率非常低, 业务不是很重要, 但是一样有相似的内存上涨曲线, 目前也达到了 85% 左右, 这个更加证实了不是业务侧的问题, 得通过修改优化 MySQL 参数来解决问题.
针对该实例, 我们直接修改了 innodb_buffer_pool_size 参数 50%, 阿里云 MySQL 重启是一个主备切换的过程,中间有几秒的只读阶段, 后续恢复之后, 内存已经迅速下探.
继续排查
虽然 实例2 的发现和操作让我们对阿里云 MySQL 服务心里有了个底, 但是 MySQL 实例1 的问题依然没有线索, 且该实例依赖的业务非常多, 重启影响较大.
几经排查, 确实也没啥有用的线索, 我也在网上查找了类似的案例, 发现大多数 MySQL 内存上涨OOM的问题都集中在 5.6 以后, 隐约感觉到会是 performance_schema 这个性能检测功能的问题.
其中一个案例关掉 performance_schema 功能, 内存下降了几百 M. 另外, 不知道阿里云的监控是否受到 performance_schema 功能的影响.
运维同事给阿里云客服提了工单, 反馈了修改 performance_schema 参数的想法, 对方回复不会有任何影响.
关键证据
我们发现 performance_schema 大约占用了 7.3 个 G! 这么大的内存占用, 那我们只要关闭 performance_schema 这个功能, 内存就降下去了, 对我们也没有什么影响.
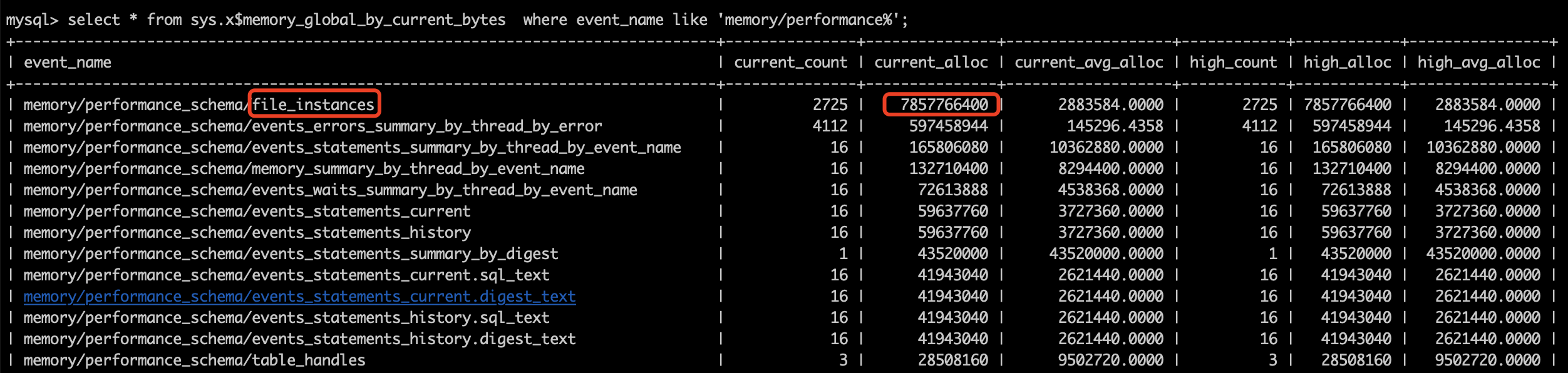
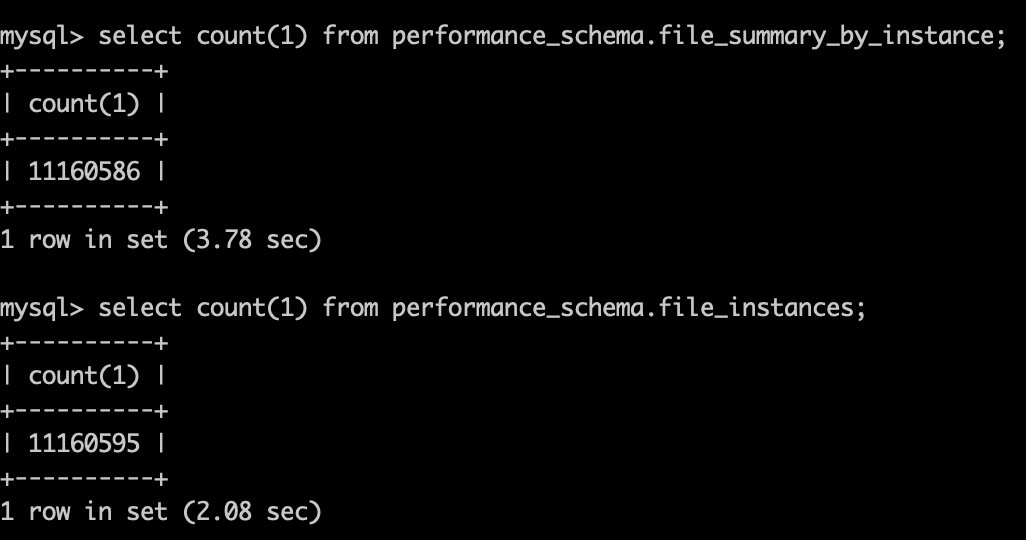
后续
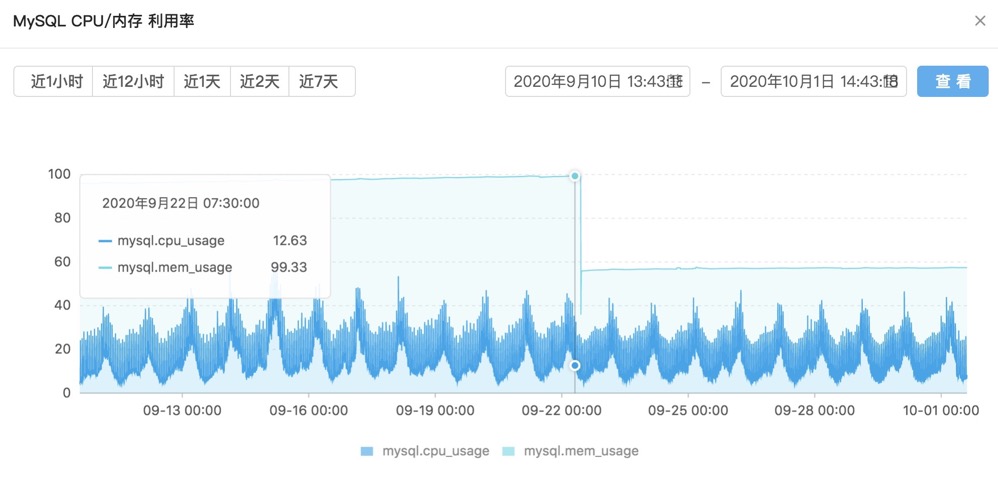
修改 performance_schema=OFF, 关掉 MySQL 性能检测后, 内存占用率已经掉到了 55% 左右, 且没有再出现持续缓慢上涨的问题.
Author hopehook
LastMod 2019-12-16